Hi again,
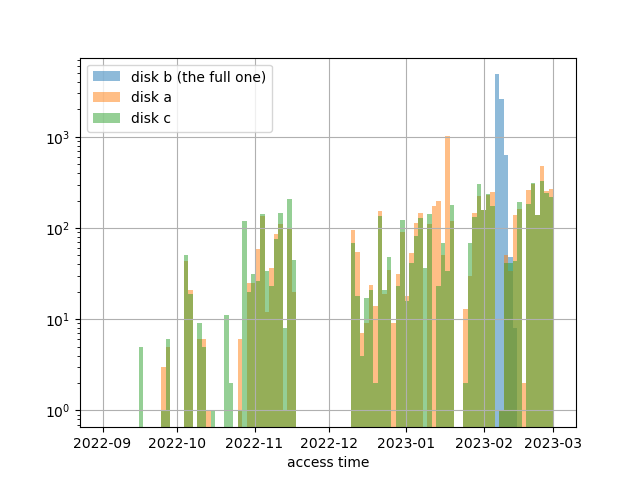
To add to this - to some extend it seems xrootd actually stops putting
stuff on that disk (see the plot attached). One can see that disk b (the
one that runs full) stops having access times after a certain date. For
comparison 2 other disks are shown. But it seems that only happens when
the disk is 100% full.
Cheers,
Nikolai
On 2/28/23 15:36, Nikolai Hartmann wrote:
> Hi Matevz,
>
>>>> I still suspect something goes wrong with the disk selection for
>>>> placement of new files -- the full disk should simply not be
>>>> chosen over the other disks and thus stop filling up
> Does that mean it should stop filling up when it reaches the high
> watermark or at 100%?
> So even if i have the situation that all my access/modification times on
> that particular disk are rather new (since i cleared it after i saw the
> issue first) you think it shouldn't happen that this disk fills up
> completely?
>
> I can try to run a custom build in a new container if you give me the
> instructions. However it probably should be on top of v5.4.2 since we
> saw issues with newer versions (very slow transfers - didn't have time
> to look in detail into that).
>
> Cheers,
> Nikolai
>
> On 2/28/23 09:05, Matevz Tadel wrote:
>> Hi Andy,
>>
>> Yeah, the code also looked good to me ... but then, if a fuller disk
>> still gets
>> selected (with assumed default oss.alloc, fuzz=0), then perhaps it's
>> the cache
>> scan that assigns the partition a wrong free space value? I'm not
>> saying the
>> problem is in xrootd, maybe somebody else is playing tricks at the
>> system/container level?
>>
>> Matevz
>>
>> On 2/27/23 23:50, Andrew Hanushevsky wrote:
>>> Hi Matevz,
>>>
>>> It is XrdOssCache::Alloc() and I will gaurantee you that it will not
>>> choose a
>>> full disk if it has properly confiurted. The default is proper so I
>>> don't know
>>> if there have been any overrides here.
>>>
>>> Andy
>>>
>>>
>>> On Mon, 27 Feb 2023, Matevz Tadel wrote:
>>>
>>>> Hi Nikolai,
>>>>
>>>> I don't think this matters, xcache uses last file access time as
>>>> written in the
>>>> cinfo file.
>>>>
>>>> I still suspect something goes wrong with the disk selection for
>>>> placement of
>>>> new files -- the full disk should simply not be chosen over the
>>>> other disks and
>>>> thus stop filling up.
>>>>
>>>> Wiping the whole cache would help, at least for a while :) ... but
>>>> it would be
>>>> good to understand what is going on here. Would you be able to run
>>>> with a custom
>>>> build? Potentially we could just replace a single library to include
>>>> some
>>>> printouts.
>>>>
>>>> Andy, remind me please ... where is the code that does disk
>>>> selection? Is it
>>>> XrdOssCache::Alloc()?
>>>>
>>>> Cheers,
>>>> Matevz
>>>>
>>>> On 2/16/23 02:27, Nikolai Hartmann wrote:
>>>>> Hi again,
>>>>>
>>>>> Actually it seems to only change the "change" time (st_ctime)
>>>>>
>>>>> touch test
>>>>> stat test
>>>>> [...]
>>>>> Access: 2023-02-16 11:25:11.962804882 +0100
>>>>> Modify: 2023-02-16 11:25:11.962804882 +0100
>>>>> Change: 2023-02-16 11:25:11.962804882 +0100
>>>>> Birth: 2023-02-16 11:25:11.962804882 +0100
>>>>>
>>>>> chown xrootd test
>>>>> stat test
>>>>> [...]
>>>>> Access: 2023-02-16 11:25:11.962804882 +0100
>>>>> Modify: 2023-02-16 11:25:11.962804882 +0100
>>>>> Change: 2023-02-16 11:25:20.322843125 +0100
>>>>> Birth: 2023-02-16 11:25:11.962804882 +0100
>>>>>
>>>>> Does this play a role?
>>>>>
>>>>> Cheers,
>>>>> Nikolai
>>>>>
>>>>> On 2/16/23 11:18, Nikolai Hartmann wrote:
>>>>>> Hi Matevz (including xrootd list again which i forgot in the last
>>>>>> reply),
>>>>>>
>>>>>>> Well, if for some reason more new files are placed on a single disk,
>>>>>>> those files will be "newer" and purge would preferentially wipe data
>>>>>>> off other disks.
>>>>>> Mhhhh - then i have an idea how i may have triggered this. As
>>>>>> mentioned in my
>>>>>> first email the issue started after i updated my container image
>>>>>> and had to
>>>>>> change the xrootd user ids. This changes the Access time of the
>>>>>> files - if
>>>>>> that is used by xrootd to determine which files are newer than it
>>>>>> could just
>>>>>> be that the chown process walked this directory last and therefore
>>>>>> will purge
>>>>>> it last.
>>>>>> When i then deleted it when the disk ran full i made the problem
>>>>>> even worse
>>>>>> since now all the files that end up there are recently accessed.
>>>>>>
>>>>>> So deleting the whole cache should fix it?
>>>>>>
>>>>>> Cheers,
>>>>>> Nikolai
>>>>>>
>>>>>> On 2/16/23 10:50, Matevz Tadel wrote:
>>>>>>> Hi Andy, Nikolai,
>>>>>>>
>>>>>>> On 2/15/23 23:51, Andrew Hanushevsky wrote:
>>>>>>>> Hi Nikolai,
>>>>>>>>
>>>>>>>> Hmm, this sounds like an off by one problem in Xcache.
>>>>>>>
>>>>>>> How? XCache does not do disks, it just uses oss API to a pool.
>>>>>>>
>>>>>>>> The question is what is
>>>>>>>> the "one". It does seem that ity consistently does not purge
>>>>>>>> files from a
>>>>>>>> particular disk but then again it doesn't know about disks. So,
>>>>>>>> there is some
>>>>>>>> systematic issue that resolves to ignoring a disk. Matevz?
>>>>>>>
>>>>>>> Well, if for some reason more new files are placed on a single
>>>>>>> disk, those
>>>>>>> files
>>>>>>> will be "newer" and purge would preferentially wipe data off
>>>>>>> other disks.
>>>>>>>
>>>>>>> That's why I asked in the first email how disks are selected for
>>>>>>> new files and
>>>>>>> if we could inject some debug printouts there.
>>>>>>>
>>>>>>> Perhaps a coincidence, but the full disk is the one that is
>>>>>>> listed first by
>>>>>>> df.
>>>>>>>
>>>>>>> The docs say default for oss.alloc fuzz = 0 and that this "forces
>>>>>>> oss to
>>>>>>> always
>>>>>>> use the partition with the largest amount of free space" -- so
>>>>>>> the fuller one
>>>>>>> should never get selected for new files. And xcache does pass the
>>>>>>> appropriate
>>>>>>> oss.asize opaque parameter to open.
>>>>>>>
>>>>>>> https://urldefense.com/v3/__https://xrootd.slac.stanford.edu/doc/dev56/ofs_config.htm*_Toc116508676__;Iw!!Mih3wA!CPJXm6eN-2_hoD2H_DidLrJJIwTvYUTK7V8pRT64GhSwBlmFYugKLfTk2O6zoR2otc1TQNvfczttg_nl$
>>>>>>> Matevz
>>>>>>>
>>>>>>>> Andy
>>>>>>>>
>>>>>>>>
>>>>>>>> On Thu, 16 Feb 2023, Nikolai Hartmann wrote:
>>>>>>>>
>>>>>>>>> Hi Andy,
>>>>>>>>>
>>>>>>>>> The behavior seems to be that it purges all the disks except
>>>>>>>>> one. After the
>>>>>>>>> other disks now again surpassed the threshold of 95% it seemed
>>>>>>>>> to trigger
>>>>>>>>> the
>>>>>>>>> cleanup and now i have this:
>>>>>>>>>
>>>>>>>>> Filesystem Type Size Used Avail Use%
>>>>>>>>> Mounted on
>>>>>>>>> /dev/sdb btrfs 5,5T 5,3T 215G 97%
>>>>>>>>> /srv/xcache/b
>>>>>>>>> /dev/sda btrfs 5,5T 5,0T 560G 90%
>>>>>>>>> /srv/xcache/a
>>>>>>>>> /dev/sdh btrfs 5,5T 4,9T 588G 90%
>>>>>>>>> /srv/xcache/h
>>>>>>>>> /dev/sdj btrfs 5,5T 4,9T 584G 90%
>>>>>>>>> /srv/xcache/j
>>>>>>>>> /dev/sdf btrfs 5,5T 4,9T 580G 90%
>>>>>>>>> /srv/xcache/f
>>>>>>>>> /dev/sdm btrfs 5,5T 5,0T 535G 91%
>>>>>>>>> /srv/xcache/m
>>>>>>>>> /dev/sdc btrfs 5,5T 5,0T 553G 91%
>>>>>>>>> /srv/xcache/c
>>>>>>>>> /dev/sdg btrfs 5,5T 4,9T 612G 90%
>>>>>>>>> /srv/xcache/g
>>>>>>>>> /dev/sdi btrfs 5,5T 4,9T 596G 90%
>>>>>>>>> /srv/xcache/i
>>>>>>>>> /dev/sdl btrfs 5,5T 5,0T 518G 91%
>>>>>>>>> /srv/xcache/l
>>>>>>>>> /dev/sdn btrfs 5,5T 4,9T 570G 90%
>>>>>>>>> /srv/xcache/n
>>>>>>>>> /dev/sde btrfs 5,5T 4,9T 593G 90%
>>>>>>>>> /srv/xcache/e
>>>>>>>>> /dev/sdk btrfs 5,5T 4,8T 677G 88%
>>>>>>>>> /srv/xcache/k
>>>>>>>>> /dev/sdd btrfs 5,5T 4,9T 602G 90%
>>>>>>>>> /srv/xcache/d
>>>>>>>>>
>>>>>>>>> Cheers,
>>>>>>>>> Nikolai
>>>>>>>>>
>>>>>>>>> On 2/14/23 21:52, Andrew Hanushevsky wrote:
>>>>>>>>>> Hi Matevz & Nikolai,
>>>>>>>>>>
>>>>>>>>>> The allocation should favor the disk with the most free space
>>>>>>>>>> unless it's
>>>>>>>>>> atered using the oss.alloc directive:
>>>>>>>>>> https://urldefense.com/v3/__https://xrootd.slac.stanford.edu/doc/dev54/ofs_config.htm*_Toc89982400__;Iw!!Mih3wA!AsisYxoXis_6IdoiqK-BwdMsHfHTB41Z4-GEjaMqvO0PQHh6TqU8Sn79JUgDeJDLCvO63yQiG63Zu6syVA$
>>>>>>>>>> I don't think Nikolai specifies that and I don't think the pfc
>>>>>>>>>> alters it in
>>>>>>>>>> any way. So, I can't explain why we see that difference other
>>>>>>>>>> than via an
>>>>>>>>>> uneven purge.
>>>>>>>>>>
>>>>>>>>>> Andy
>>>>>>>>>>
>>>>>>>>>>
>>>>>>>>>> On Tue, 14 Feb 2023, Matevz Tadel wrote:
>>>>>>>>>>
>>>>>>>>>>> Hi Nikolai, Andy,
>>>>>>>>>>>
>>>>>>>>>>> I saw this a long time back, 2++ years. The thing is that
>>>>>>>>>>> xcache does oss
>>>>>>>>>>> df on
>>>>>>>>>>> the whole space and then deletes files without any knowledge
>>>>>>>>>>> of the
>>>>>>>>>>> usage on
>>>>>>>>>>> individual disks themselves. Placement of new files should
>>>>>>>>>>> prefer the more
>>>>>>>>>>> empty
>>>>>>>>>>> disks though, iirc.
>>>>>>>>>>>
>>>>>>>>>>> I remember asking Andy about how xcache could be made aware
>>>>>>>>>>> of individual
>>>>>>>>>>> disks
>>>>>>>>>>> and he prepared something for me but it got really
>>>>>>>>>>> complicated when I was
>>>>>>>>>>> trying
>>>>>>>>>>> to include this into the cache purge algorithm so I think I
>>>>>>>>>>> dropped this.
>>>>>>>>>>>
>>>>>>>>>>> Andy, could we sneak some debug printouts into oss new file disk
>>>>>>>>>>> selection to
>>>>>>>>>>> see if something is going wrong there?
>>>>>>>>>>>
>>>>>>>>>>> Nikolai, how fast does this happen? Is it a matter of days,
>>>>>>>>>>> ie, over many
>>>>>>>>>>> purge
>>>>>>>>>>> cycles? Is it always the same disk?
>>>>>>>>>>>
>>>>>>>>>>> Cheers,
>>>>>>>>>>> Matevz
>>>>>>>>>>>
>>>>>>>>>>> On 2/13/23 23:21, Nikolai Hartmann wrote:
>>>>>>>>>>>> Hi Andy,
>>>>>>>>>>>>
>>>>>>>>>>>> The config is the following:
>>>>>>>>>>>>
>>>>>>>>>>>> https://urldefense.com/v3/__https://gitlab.physik.uni-muenchen.de/etp-computing/xcache-nspawn-lrz/-/blob/086e5ade5d27fc7d5ef59448c955523e453c091f/etc/xrootd/xcache.cfg__;!!Mih3wA!DfZZQn5-SZKaGYvPW97K8SD5gDYYTy0wuUgMgQCUMhwQehl01yhKQdErjCRUz3BoZYL_nKVipwRIRYyR$
>>>>>>>>>>>> The directories for `oss.localroot` and `oss.space meta` are
>>>>>>>>>>>> on the
>>>>>>>>>>>> system
>>>>>>>>>>>> disk.
>>>>>>>>>>>> The `/srv/xcache/[a-m]` are individually mounted devices.
>>>>>>>>>>>>
>>>>>>>>>>>> Best,
>>>>>>>>>>>> Nikolai
>>>>>>>>>>>>
>>>>>>>>>>>> On 2/14/23 00:34, Andrew Hanushevsky wrote:
>>>>>>>>>>>>> Hi Nikolai,
>>>>>>>>>>>>>
>>>>>>>>>>>>> Hmmm, no it seems you are the first one. Then again, not
>>>>>>>>>>>>> many people
>>>>>>>>>>>>> have a
>>>>>>>>>>>>> multi-disk setup. So, could you send a link to your config
>>>>>>>>>>>>> file? It
>>>>>>>>>>>>> might be
>>>>>>>>>>>>> the case that all of the metadata files wind up on the same
>>>>>>>>>>>>> disk and
>>>>>>>>>>>>> that is
>>>>>>>>>>>>> the source of the issue here.
>>>>>>>>>>>>>
>>>>>>>>>>>>> Andy
>>>>>>>>>>>>>
>>>>>>>>>>>>> On Mon, 13 Feb 2023, Nikolai Hartmann wrote:
>>>>>>>>>>>>>
>>>>>>>>>>>>>> Dear xrootd-l,
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> I'm seeing the issue that one of the disks on one of our
>>>>>>>>>>>>>> xcache servers
>>>>>>>>>>>>>> fills
>>>>>>>>>>>>>> up disproportionally - that means it runs completely full
>>>>>>>>>>>>>> until i
>>>>>>>>>>>>>> get "no
>>>>>>>>>>>>>> space left on device" errors without xcache running
>>>>>>>>>>>>>> cleanup, while the
>>>>>>>>>>>>>> other
>>>>>>>>>>>>>> disks still have plenty of space left. My current df output:
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> /dev/sdb btrfs 5,5T 5,2T 273G 96%
>>>>>>>>>>>>>> /srv/xcache/b
>>>>>>>>>>>>>> /dev/sda btrfs 5,5T 4,9T 584G 90%
>>>>>>>>>>>>>> /srv/xcache/a
>>>>>>>>>>>>>> /dev/sdh btrfs 5,5T 5,0T 562G 90%
>>>>>>>>>>>>>> /srv/xcache/h
>>>>>>>>>>>>>> /dev/sdj btrfs 5,5T 5,0T 551G 91%
>>>>>>>>>>>>>> /srv/xcache/j
>>>>>>>>>>>>>> /dev/sdf btrfs 5,5T 4,9T 579G 90%
>>>>>>>>>>>>>> /srv/xcache/f
>>>>>>>>>>>>>> [...]
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> If you look at the first line you see that disk is 96%
>>>>>>>>>>>>>> full while the
>>>>>>>>>>>>>> others
>>>>>>>>>>>>>> are around 90%. The issue occurred the first time after i
>>>>>>>>>>>>>> built a new
>>>>>>>>>>>>>> container for running xrootd. That change involved
>>>>>>>>>>>>>> switching the
>>>>>>>>>>>>>> container
>>>>>>>>>>>>>> from centos7 to almalinux8 and changing the xrootd user id
>>>>>>>>>>>>>> (ran
>>>>>>>>>>>>>> chown and
>>>>>>>>>>>>>> chgrp afterwards on the cache directories which are bind
>>>>>>>>>>>>>> mounted). The
>>>>>>>>>>>>>> xrootd
>>>>>>>>>>>>>> version stayed the same (5.4.2). The high/low watermark
>>>>>>>>>>>>>> configuration
>>>>>>>>>>>>>> is the
>>>>>>>>>>>>>> following:
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> pfc.diskusage 0.90 0.95
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> I already tried clearing the misbehaving disk (after it
>>>>>>>>>>>>>> ran full to
>>>>>>>>>>>>>> 100%),
>>>>>>>>>>>>>> but now the issue is reappearing. Has anyone seen similar
>>>>>>>>>>>>>> issues or
>>>>>>>>>>>>>> does it
>>>>>>>>>>>>>> ring any bells for you?
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> One thing i checked is the size that xrootd reports in the
>>>>>>>>>>>>>> log for the
>>>>>>>>>>>>>> total
>>>>>>>>>>>>>> storage and that at least matches what i get when i sum
>>>>>>>>>>>>>> the entries
>>>>>>>>>>>>>> from
>>>>>>>>>>>>>> `df`.
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> Cheers,
>>>>>>>>>>>>>> Nikolai
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> ########################################################################
>>>>>>>>>>>>>> Use REPLY-ALL to reply to list
>>>>>>>>>>>>>>
>>>>>>>>>>>>>> To unsubscribe from the XROOTD-L list, click the following
>>>>>>>>>>>>>> link:
>>>>>>>>>>>>>> https://urldefense.com/v3/__https://listserv.slac.stanford.edu/cgi-bin/wa?SUBED1=XROOTD-L&A=1__;!!Mih3wA!DfZZQn5-SZKaGYvPW97K8SD5gDYYTy0wuUgMgQCUMhwQehl01yhKQdErjCRUz3BoZYL_nKVip_SnON6x$
>>>>>>>>>>>
>>>>>>>>>
>>>>>>>
>>>>
>>
########################################################################
Use REPLY-ALL to reply to list
To unsubscribe from the XROOTD-L list, click the following link:
https://listserv.slac.stanford.edu/cgi-bin/wa?SUBED1=XROOTD-L&A=1
|















{kind=link}